When Silence Is the Bug
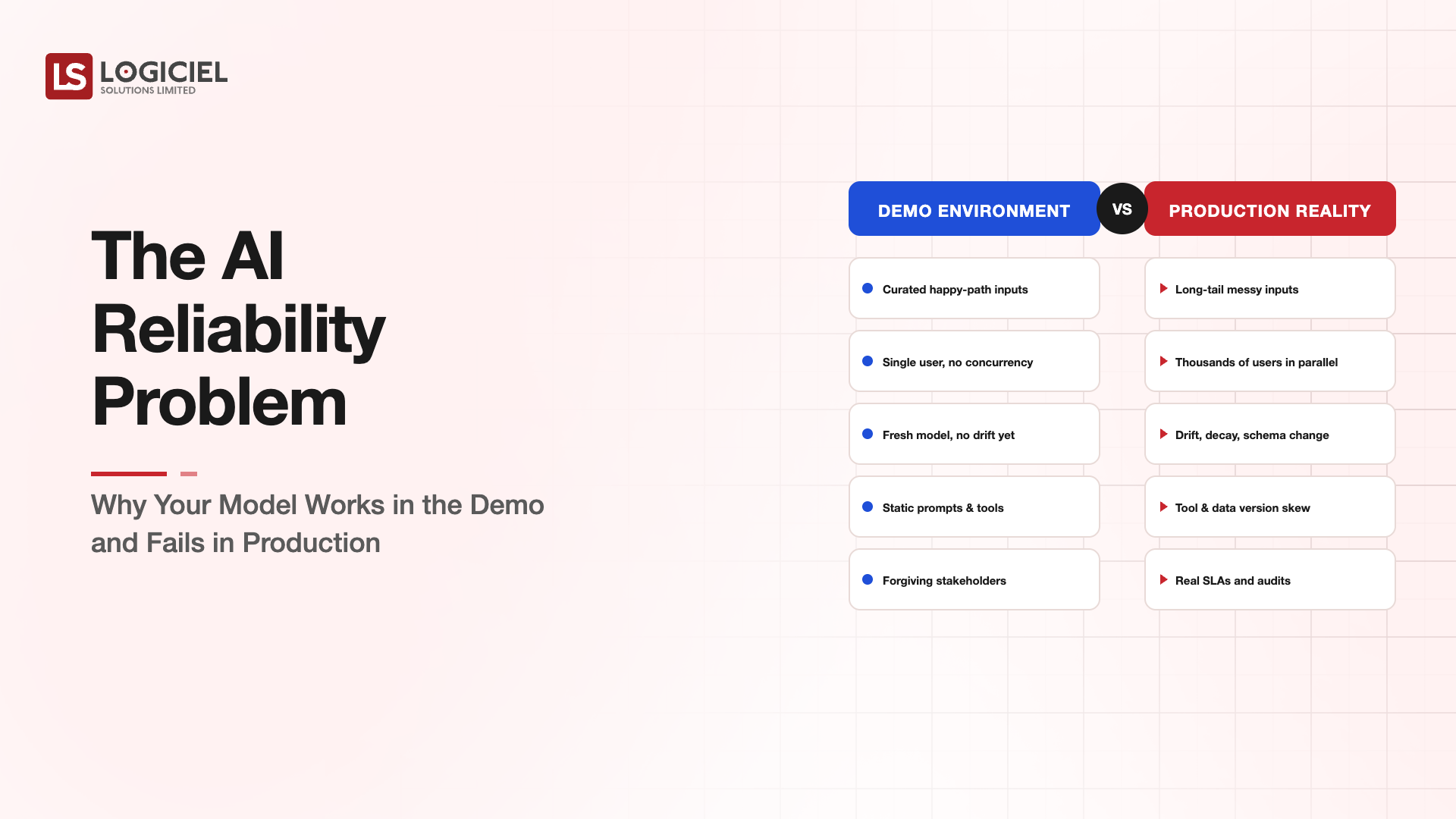
The classic outage is a 500 error. The dashboard turns red, somebody gets paged, the war room opens.
The 2026 outage looks different. The application is up. The dashboard is green. The model is returning responses at normal latency with no error rate increase. Quality has degraded by 30 percent and nobody knows yet.
MIT's 2024 study of 122 production AI deployments found 91 percent had measurable performance drift within 12 months. 67 percent of those drifts went undetected by the deployment team's existing monitoring (MIT Sloan, "Closing the AI Reliability Gap," 2024).
Silent failure is the new outage. Your existing reliability practices were designed for systems that fail loudly. Continuous intelligence systems fail quietly. The reliability stack has to follow.
AI – Powered Product Development Playbook
How AI-first startups build MVPs faster, ship quicker, & impress investors without big teams.
Coined Frame: The Four New Reliability Surfaces
Software reliability for AI-integrated systems lives on four surfaces, not one. Most teams are monitoring one or two and calling it done.
Surface 1 - Infrastructure. The classic reliability surface. Uptime, latency, error rate, capacity. This is the surface every SRE team already covers. AI workloads add GPU memory pressure, model inference timeout patterns, and rate-limit handling, but it is still recognizable SRE territory.
Surface 2 - Output quality. Is the model producing answers at the quality bar you committed to. Hallucination rate, factual accuracy on a fixed eval set, response coherence on production traffic. This surface is new for most teams. It requires running evals continuously against production samples, not just before each deploy.
Surface 3 - Behavioral consistency. Is the model behaving the same way it did last week. Distribution shifts in response patterns, tone drift, refusal-rate changes after a model provider update. This is where the silent failure usually lives. Most teams have nothing watching this surface today.
Surface 4 - Cost and resource consumption. Is the cost per request stable. Inference cost spikes typically precede or accompany behavioral drift and can be the first signal that something has changed upstream.
Coverage on all four surfaces is what reliability means now. Coverage on Surface 1 alone is what we used to call reliability and what now constitutes a partial deployment.
The Four-Minute Detection Bar
Amazon Web Services published data in late 2025 on their internal DevOps Agent showing mean time to detection for production regressions of 4 minutes (AWS, "DevOps Agent at re:Invent 2024," 2024). The comparison number for human-monitored systems with standard observability tooling sat at 47 minutes.
The 4-minute bar is not aspirational. It is real and shipping at one of the largest engineering organizations on earth. The gap matters because in a continuous intelligence system the cost of slow detection compounds. Every request between detection and resolution is delivered at degraded quality. Customer trust is a leaky bucket.
Closing the 47-to-4 minute gap requires three things most teams do not have yet. Continuous eval running against production traffic. Behavioral monitoring on aggregated response patterns, not just individual requests. And automated rollback for regressions that cross thresholds.
The Drift Categories
When models drift, they drift in patterns. Three are common enough to plan for.
Data drift. Your inputs changed. The customer mix shifted, the document format changed, a new product feature is sending queries the model has not seen. Detection comes from monitoring the input distribution, not just the model output.
Model drift. Your provider updated the model. OpenAI, Anthropic, Google, every major API has versioned models, and the major providers also push silent updates within a version. Pinning model versions and running eval gates on provider updates catches this.
Prompt drift. The team made changes to system prompts, retrieval pipelines, or context construction without running full evals. This is the most common drift cause in production AI systems and the easiest to prevent with prompt-versioning discipline.
Knowing which kind of drift you are looking at tells you which fix sequence runs. Mixing them up wastes a war room.
The Reliability Stack That Actually Ships
Here is the stack that high-functioning AI engineering teams are running in 2026.
At the infrastructure surface, standard SRE tooling. Prometheus, Datadog, AWS CloudWatch, with AI-specific dashboards for inference latency, GPU utilization, and rate-limit consumption.
At the quality surface, continuous eval. A fixed eval set running against the production model on a schedule, plus a sampling pipeline that runs a smaller eval against actual production traffic. Tooling here is still consolidating, but Langfuse, Helicone, and the major MLOps platforms now cover this layer with usable products.
At the behavioral surface, response monitoring. Aggregated metrics on response length, refusal rate, sentiment, structured output adherence, citation accuracy. Anomaly detection on the aggregate, not on individual requests.
At the cost surface, per-request cost tracking with anomaly detection. A sudden spike in tokens per request is often the first signal of something else changing upstream.
Tying it together, automated rollback. If the quality, behavioral, or cost surface crosses a threshold, the system rolls back to the previous prompt version, the previous model version, or the previous retrieval pipeline. Human pages happen, but degradation is bounded.
This is what closes the 47-to-4-minute gap.
What This Costs
Building this stack from scratch on top of an existing AI product is roughly a quarter of dedicated platform engineering time, scaled to team size. For most mid-market companies that is two senior engineers for a quarter. The ROI calculation is the cost of one silent quality outage that escapes to customers, which is almost always larger than the build cost.
Mature teams that already have observability mature on Surfaces 1 and 4 can usually close the gap on Surfaces 2 and 3 in six to eight weeks.
100 CTOs. Real Expectations
This report shows what actually predicts delivery success and what CTOs discover too late.
Call to Action
What Logiciel Does Here
Logiciel works with engineering teams operating AI features that are now load-bearing on revenue or customer experience. The reliability work is usually where we start, because if the system is not reliably observable you cannot reliably improve anything else.
The AI Reliability Framework covers the four-surface model in more depth and is the document we walk new engagements through. The CTO AI Evaluation Framework covers the reliability bar that should sit inside any vendor or partner contract for AI engineering work.
If you are running into silent quality issues today, a 30-minute working session is usually enough to map your current coverage against the four surfaces and surface the first gap to close.
Frequently Asked Questions
How often should I re-run evals against my production model?
A full eval set against every model provider update, every prompt change, and at minimum weekly on a schedule. A sampling eval against production traffic continuously, ideally with results piped to the same observability dashboard your SRE team uses for infrastructure.
What is the right eval set size?
Smaller than people think and broader than people think. 200 to 500 examples covering the high-traffic intents, the high-risk edge cases, and the most recent customer-reported issues. Larger sets cost more to run and tend to be neglected. Smaller sets miss too much.
Can I use the model provider's own monitoring tools?
For Surface 1 yes, partially. For Surfaces 2 and 3, no. The provider's monitoring sees their slice. Your application is downstream of their model plus your retrieval, your prompts, your routing logic. You need monitoring at the application surface, not the model surface.
When does automated rollback help and when does it hurt?
It helps when the rollback target is well-tested and the threshold is calibrated. It hurts when the threshold is too sensitive and the system flaps between versions, or when the rollback target itself has issues. Start manual, run drills, then automate the well-understood paths.
What is the most common reliability failure I should plan for?
Provider model updates that the team did not notice. Either a silent update within a version, or a forced migration when a version reaches end of life. Calendar checks against provider release notes, version pinning where possible, and pre-staged eval runs against any update before it reaches production traffic. Sources: - MIT Sloan, "Closing the AI Reliability Gap," 2024 - AWS DevOps Agent announcement, re:Invent 2024 - DORA State of DevOps 2024